Alejandro Páez
Sysadmin & Especialista en Redes ISP
14+ años operando backbone de ISP. Reduje incidentes nocturnos en un 80% con automatización, observabilidad en tiempo real e IA aplicada al trabajo técnico.
- Cluster Proxmox +7 nodos
- +50 VMs en producción
- Alertas en tiempo real (Zabbix + Telegram)
Problemas que resuelvo
Infraestructura crítica de ISP, sistemas Linux y automatización para que servicios core funcionen 24/7 sin sorpresas.
Redes ISP estables
BGP, ruteo, VLANs, VPNs, WISP, FTTH/ADSL y redundancia/balanceo para servicios 24/7.
Virtualización operable
Cluster Proxmox +7 nodos, +50 VMs en producción y backups en caliente con PBS.
Observabilidad accionable
Zabbix, Grafana, Nagios y alertas por bot de Telegram para reducir incidentes nocturnos.
Servicios corporativos
Correo con Postfix/Dovecot, DKIM/SPF/DMARC, VoIP con Asterisk/Issabel y colaboración interna.
IA aplicada a operación técnica
Codex, Claude, OpenCode, Gemini y Ollama para troubleshooting, documentación, automatización y revisión de cambios.
Casos destacados
Implementaciones reales en ISP, con foco en estabilidad operativa, automatización y resultados medibles.
RPO 1 h · RTO 30-60 minCluster Proxmox + PBS
- Problema: escalar entornos de producción y desarrollo con continuidad operativa.
- Qué hice: implementé un cluster Proxmox con +7 nodos en producción y desarrollo.
- Resultado: backups en caliente automatizados con Proxmox Backup Server.
- Proxmox VE
- Proxmox Backup Server
Ver detalle2 IPT · 5 CDNs · 2 peeringsPeering BGP y ruteo ISP
- Problema: crecimiento de una topología con upstreams, CDNs y tráfico entregado a terceros.
- Qué hice: operé BGP multi-homed con políticas de ruteo, filtros RPKI/IRR y priorización CDN.
- Resultado: 2 upstreams IPT, 2 CDNs externas, 3 CDNs locales y 2 peerings hacia clientes externos.
Ver detalleMTTR 90 min a 30 minObservabilidad y alertas en tiempo real
- Problema: baja visibilidad y alertas tardías en routers y servidores críticos.
- Qué hice: implementé Zabbix + Nagios + Grafana con alertas vía bot de Telegram.
- Resultado: alertas en tiempo real para infraestructura y servicios core.
- Zabbix
- Nagios
- Grafana
- Telegram Bot
Ver detalle50-60 VMs · uptime 99.5%-99.9%Gestión de +50 VMs en producción
- Problema: administrar servicios open source en producción a escala.
- Qué hice: implementé y gestioné más de 50 VMs para servicios críticos.
- Resultado: operación sostenida de correo, VoIP, monitoreo, colaboración y gestión interna.
Ver detalle Experiencia Profesional
Sobre mí
Diseño y opero infraestructura crítica para ISPs desde hace más de 14 años. Mi stack abarca BGP, ruteo ISP, Proxmox (cluster +7 nodos), Zabbix/Grafana, correo corporativo y VoIP. Combino arquitectura de red, sistemas Linux, automatización e IA aplicada para que los servicios funcionen 24/7 sin sorpresas.
- Infraestructura crítica: BGP, ruteo, IPv4 y alta disponibilidad para servicios 24/7.
- Virtualización a escala: clúster Proxmox +7 nodos, +50 VMs en producción y backups en caliente con PBS.
- Observabilidad en tiempo real: Zabbix + Grafana con alertas por bot de Telegram.
- IA aplicada: agentes de código, LLMs locales y revisión asistida para acelerar diagnóstico, documentación y entrega técnica.
Impulso la transformación digital del ISP con automatización, colaboración (Nextcloud, Kanboard) y servicios corporativos como correo (Postfix/Dovecot con DKIM/SPF/DMARC) y VoIP (Asterisk/Issabel).
- Redes: diseño y operación de peers BGP (políticas y filtros), ruteo estático/dinámico, VLANs, VPNs (IPSec/L2TP/OpenVPN/WireGuard), enlaces WISP y acceso FTTH/ADSL; redundancia/balanceo y continuidad operativa.
- Sistemas: servidores físicos/virtuales con Proxmox (clúster y PBS), Linux (Ubuntu/Debian/CentOS), Nginx/Apache, Docker Compose y automatización con scripts.
- Observabilidad & Seguridad: Nagios, Zabbix, Grafana, FreeRADIUS, hardening, monitoreo de tráfico (carriers/usuarios), Let’s Encrypt, buenas prácticas de ciberseguridad.
- Gestión & Liderazgo: soporte N2/N3, formación del equipo, coordinación entre áreas (red, NOC, campo, soporte), servicios de datacenter (VMs/housing) y procurement de routers/OLTs/ONTs.
- IA aplicada: Codex, Claude, OpenCode, Gemini, Ollama/Open WebUI, prompt engineering práctico y revisión asistida por Git.
Supervisor de Tecnología e Innovación — Ecolan Internet - Soluciones Tecnológicas
Febrero 2024 — Presente
- Estandaricé la observabilidad con Zabbix + Grafana y alertas por bot de Telegram, reduciendo los incidentes nocturnos en un 80%.
- Automaticé procesos operativos y consolidé servicios corporativos (correo y VoIP) con continuidad 24/7.
- Definí prácticas de continuidad y escalabilidad sostenidas por backups en caliente con PBS (RPO 1 h · RTO 30-60 min).
Coordinador de Soporte Técnico y Atención al Cliente — Ecolan Internet - Soluciones Tecnológicas
Junio 2020 — Enero 2024
- Coordiné el soporte N2/N3 y la articulación con NOC y campo, acortando el MTTR de incidentes core de 90 a 30 minutos.
- Gestioné incidentes con guardia pasiva sosteniendo un uptime de 99,5%-99,9% en servicios críticos.
- Formé al equipo y mejoré procesos de atención para escalar y documentar casos de forma consistente.
HelpDesk N1/N2/N3 — Ecolan Internet - Soluciones Tecnológicas
Julio 2011 — Diciembre 2023
- Resolví incidentes de conectividad y servicios en niveles N1, N2 y N3 a lo largo de más de 12 años de operación ISP.
- Sostuve infraestructura de red y sistemas en entornos de alta disponibilidad 24/7.
- Escalé y documenté casos críticos, construyendo la base de runbooks reutilizables del equipo.
Skills
Sistemas e Infraestructura
IA aplicada a redes, sistemas y automatización
Uso IA generativa, agentes de código y modelos locales como copilotos técnicos para acelerar diagnóstico, documentación, automatización y revisión de cambios en entornos de infraestructura. Trabajo con contexto acotado, datos protegidos, validación local, Git diff y revisión humana antes de aplicar cambios.
01Contexto
Repo, objetivo, restricciones, datos sensibles y límites de lo que no debe salir.
02Plan
Hipótesis, alcance, archivos afectados, criterio de validación y rollback.
03Ejecución
Agente o modelo correcto según riesgo: nube, local, CLI o revisión manual.
04Cierre
Diff revisado, pruebas, documentación, commit trazable y aprendizaje reutilizable.
Impacto operativo
- Diagnóstico inicial más rápido en incidentes repetitivos mediante análisis asistido de logs, métricas y runbooks.
- Documentación operativa más consistente para procedimientos de infraestructura.
- Menos riesgo en cambios productivos al exigir diff, validación local y revisión humana.
- Mejor clasificación de señales antes de alertar o bloquear, reduciendo falsos positivos.
Diagnóstico de infraestructura
Análisis asistido de logs, métricas, errores, configuraciones y runbooks para llegar antes a una hipótesis técnica verificable.
Agentes de código por repo
Uso Codex, Claude, OpenCode y Gemini con reglas por proyecto para implementar cambios chicos, revisar diffs y sostener criterios técnicos.
LLM local y datos sensibles
Uso Ollama y Open WebUI para flujos donde conviene mantener contexto operativo dentro de infraestructura propia.
Automatización y scripts
Acelero CLI tools, parsers, integraciones API, scripts de operación y documentación ejecutable sin perder revisión humana.
Seguridad operativa
Uso LLM como capa de apoyo para clasificar contexto, explicar señales y reducir falsos positivos; nunca como autoridad única de bloqueo.
Calidad, control y trazabilidad
Cada cambio asistido termina con revisión humana, lint, build, tests cuando aplica, Git diff, documentación y commit trazable.
Evidencia en proyectos
- CentinelaOllama local dentro del pipeline de threat intel para clasificar contexto y reducir falsos positivos antes de alertar o bloquear.
- Infra docs / runbooksProcedimientos de Ollama/Open WebUI y análisis de logs Elastic/Proxmox con modelo local y salida operativa.
- PortfolioNext.js, reglas CONTENT/AGENTS, capturas anonimizadas, validación local y flujo de commits asistido por Codex.
- Reglas por repoAGENTS.md, CLAUDE.md, RTK.md y prompts específicos en proyectos técnicos para dar contexto estable a agentes de código.
- Dashboards y CLIsRevisión asistida para herramientas Python/JavaScript con APIs, cache, reportes, dashboards locales y flujos de operación.
Controles que aplico
- No publicar secretos, credenciales ni datos productivos crudos.
- Usar LLM local cuando el contexto operativo no debe salir.
- Trabajar con alcance acotado por repo, archivo o tarea.
- Validar con lint, build, tests o prueba manual reproducible.
- Revisar Git diff antes de aceptar cambios.
- Documentar decisión, evidencia y rollback cuando aplica.
Principio: la IA propone, el operador valida.
Proyectos
Herramientas, automatizaciones y dashboards desarrollados para operaciones reales.
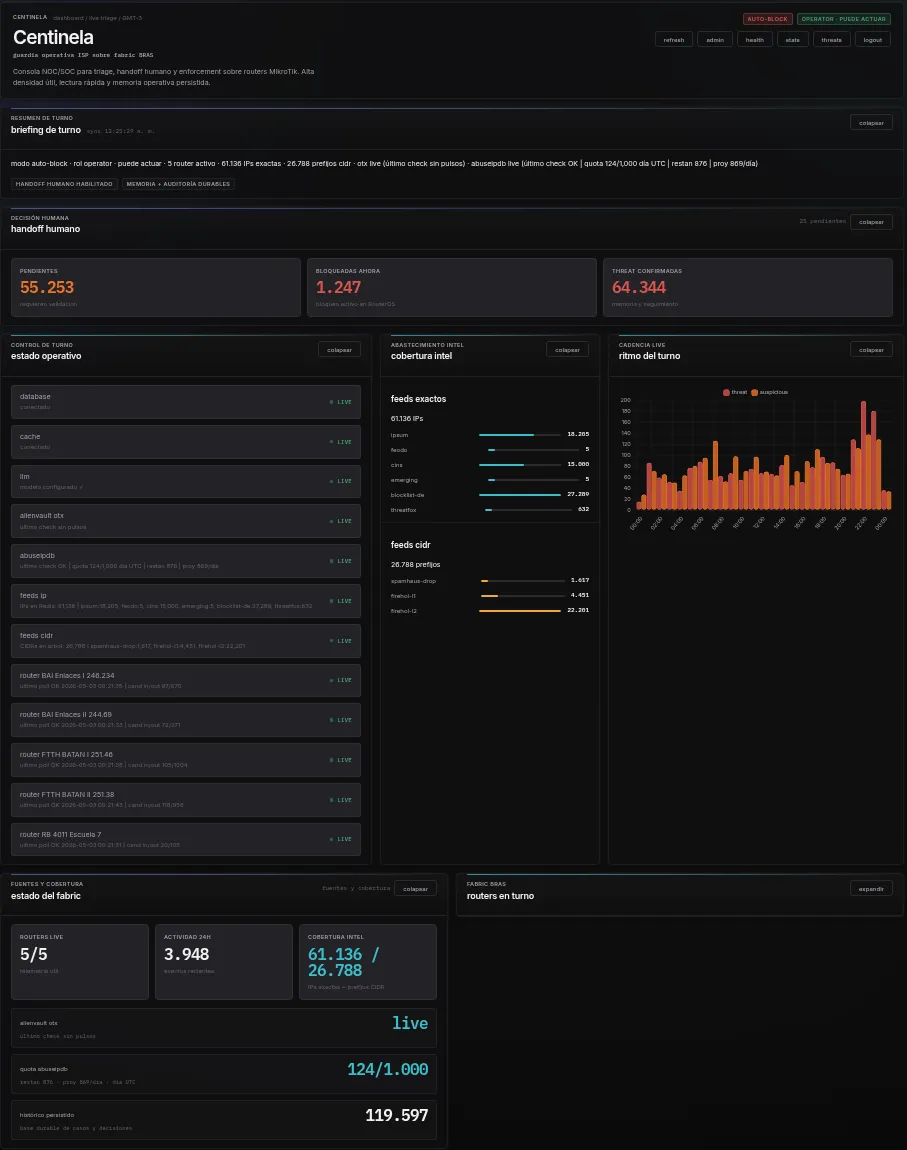
Detección y bloqueo automático de amenazas de red en tiempo real para ISPs. Monitorea conexiones de routers MikroTik vía API y bloquea IPs maliciosas con inteligencia de amenazas multicapa.
- MikroTik API
- AbuseIPDB
- Ollama
- GeoIP
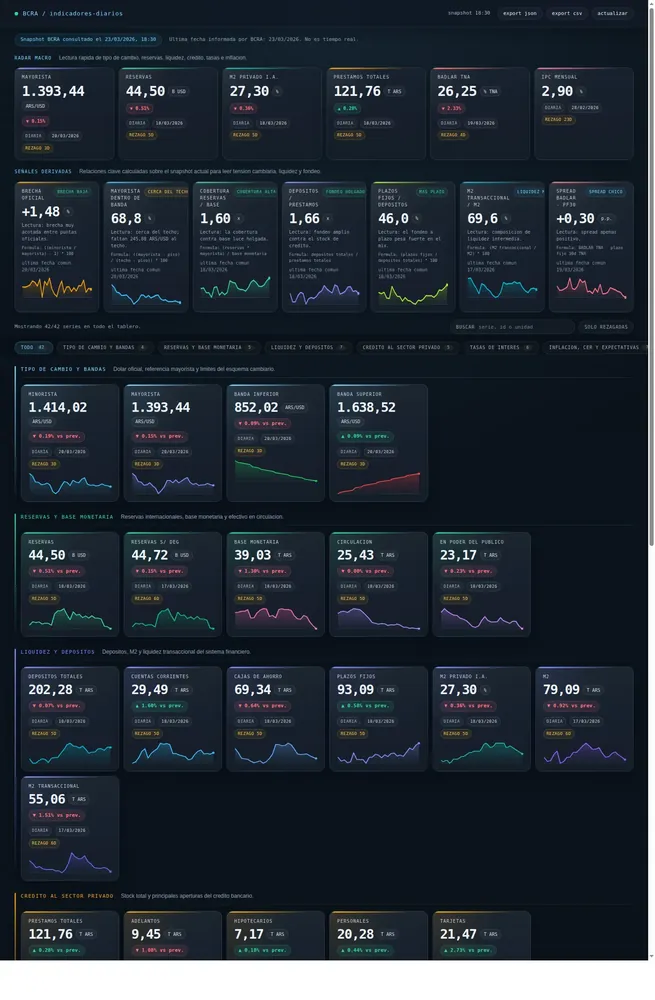
Repositorio privadoDashboard local para seguir indicadores del BCRA desde una sola pantalla. Combina proxy HTTP en Python, cache local con fallback stale y frontend estático sin dependencias externas.
- Proxy HTTP
- Cache stale
- Frontend estático
- BCRA API
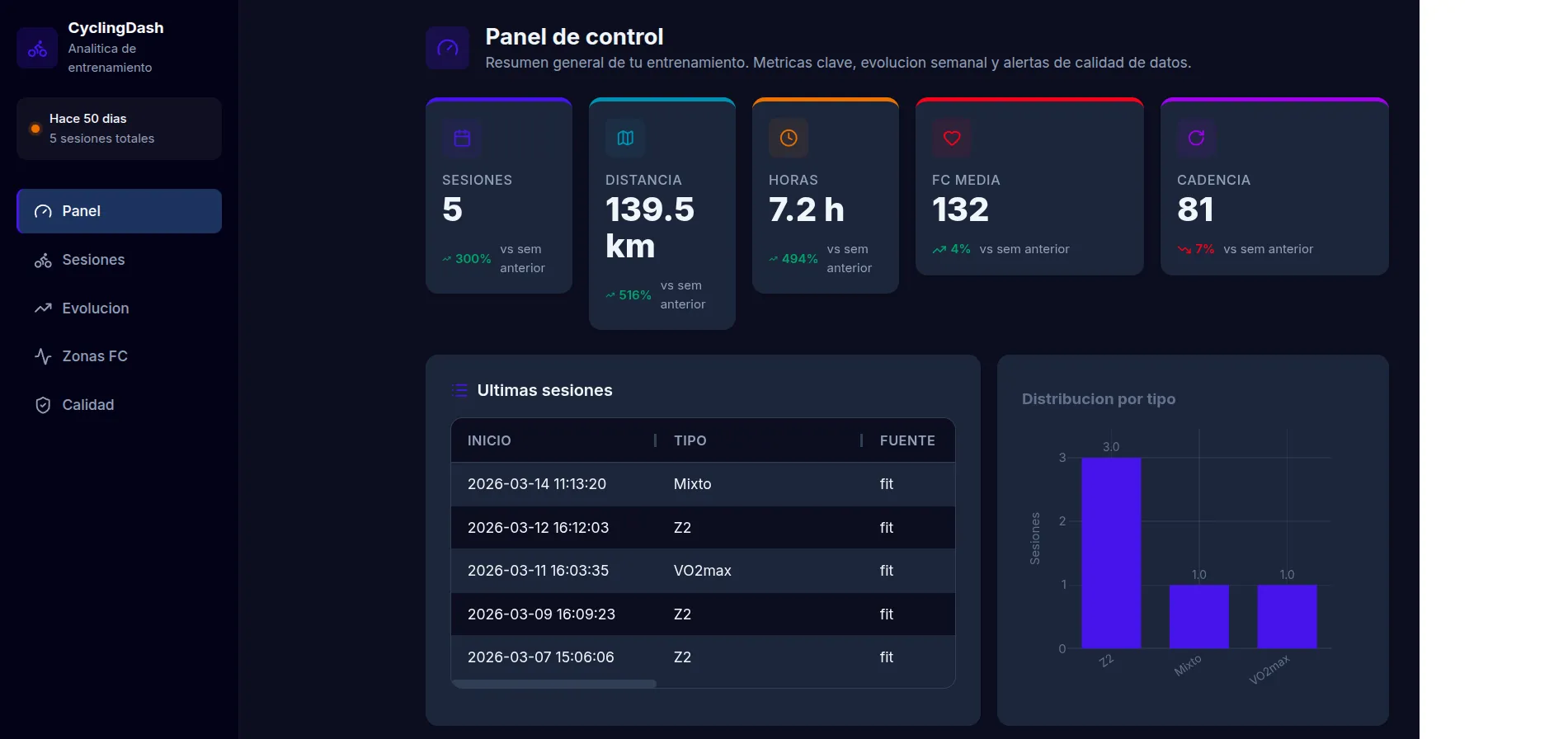
Ver repositorioDashboard de análisis de datos de ciclismo. Importa, consolida y visualiza entrenamientos con ingesta desacoplada, almacenamiento en DuckDB y gráficos interactivos con Dash + Plotly.
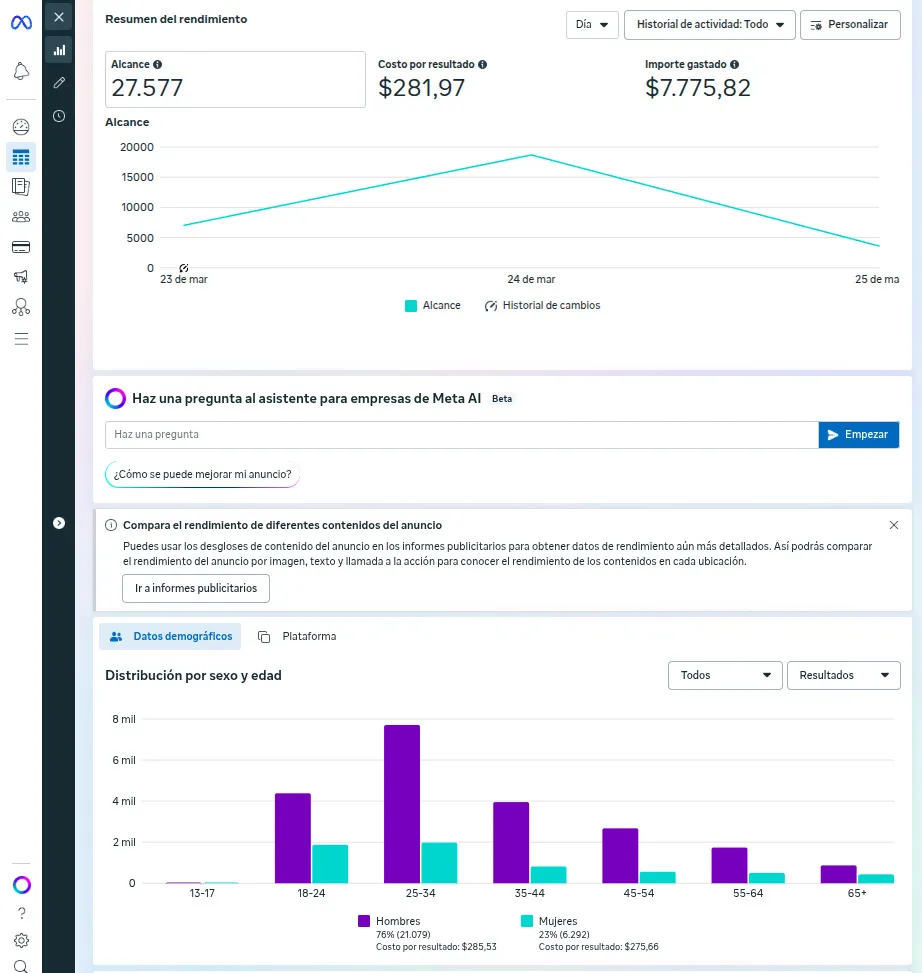
Ver repositorioToolkit CLI para revisar, crear y monitorear campañas de Meta Ads. Valida acceso a Marketing API, lista campañas, crea variantes y levanta un dashboard local de métricas.
- Meta API
- CLI Python
- Dashboard
- Reporting
Ver repositorioPortfolio profesional. Next.js 16, TypeScript, Tailwind CSS, exportación estática. Casos de estudio, proyectos, certificaciones y contacto.
- Next.js 16
- TypeScript
- Tailwind CSS
- Static Export
Repositorio privadoCertificaciones & Capacitaciones